Maple Proxy Documentation

Introducing Maple Proxy: OpenAI-Compatible API Access to Private LLMs
Want to use Maple's secure LLMs with your existing OpenAI code? Today we're excited to announce Maple Proxy, a lightweight proxy server that brings OpenAI-compatible API access to Maple's end-to-end encrypted LLM service. With Maple Proxy, developers can integrate private, secure AI completions into their applications using any OpenAI client library, no code changes required.
Why a Proxy?
Maple runs all LLM inference inside Trusted Execution Environments (TEEs), providing hardware-level security and privacy for your AI workloads. This means your prompts and responses are encrypted end-to-end and never accessible to anyone, not even Maple.
However, this security comes with complexity. Every request requires:
- Trusted Execution Environment (TEE) attestation verification to ensure you're talking to genuine secure hardware
- End-to-end encryption negotiation
- Secure key exchange protocols
Maple Proxy handles all this for you. It acts as a bridge between your standard OpenAI-compatible client and Maple's secure infrastructure, managing the attestation handshake and encryption so you don't have to.
Available Models & Pricing
Maple Proxy provides access to a growing selection of state-of-the-art models. For detailed model capabilities and example prompts, see our comprehensive model guide.
| Model | Description | Price per Million Tokens |
|---|---|---|
| gpt-oss-120b | ChatGPT creativity & structured data | $1.50 input / $2.50 output |
| kimi-k2.5 | Complex agentic workflows, multi-step coding, math, image analysis | $3 input / $10.50 output |
| deepseek-r1-0528 | Research, advanced math, coding | $3 input / $10.50 output |
| llama-3.3-70b | Therapy notes, daily tasks, general reasoning | $3.50 input / $5.50 output |
| qwen3-vl-30b | Image and video analysis, screenshot-to-code, OCR, GUI automation | $2.50 input / $8 output |
| leon-se/gemma-3-27b-it-fp8-dynamic | Blazing-fast image analysis | $10 input / $10 output |
API usage draws from the paid subscription plan credits first. If additional credits are needed, they can be purchased in increments starting at $10.
Two Ways to Get Started
Option 1: Desktop App with Built-in Proxy (Easiest for Local Development)
The Maple desktop app includes an integrated proxy server that automatically handles all configuration:
- Download the Maple app from trymaple.ai/downloads
- Sign up and upgrade to Pro, Team, or Max plan (starting at $20/month)
- Navigate to API Management in the app settings
- Open the Local Proxy tab and click "Start Proxy"
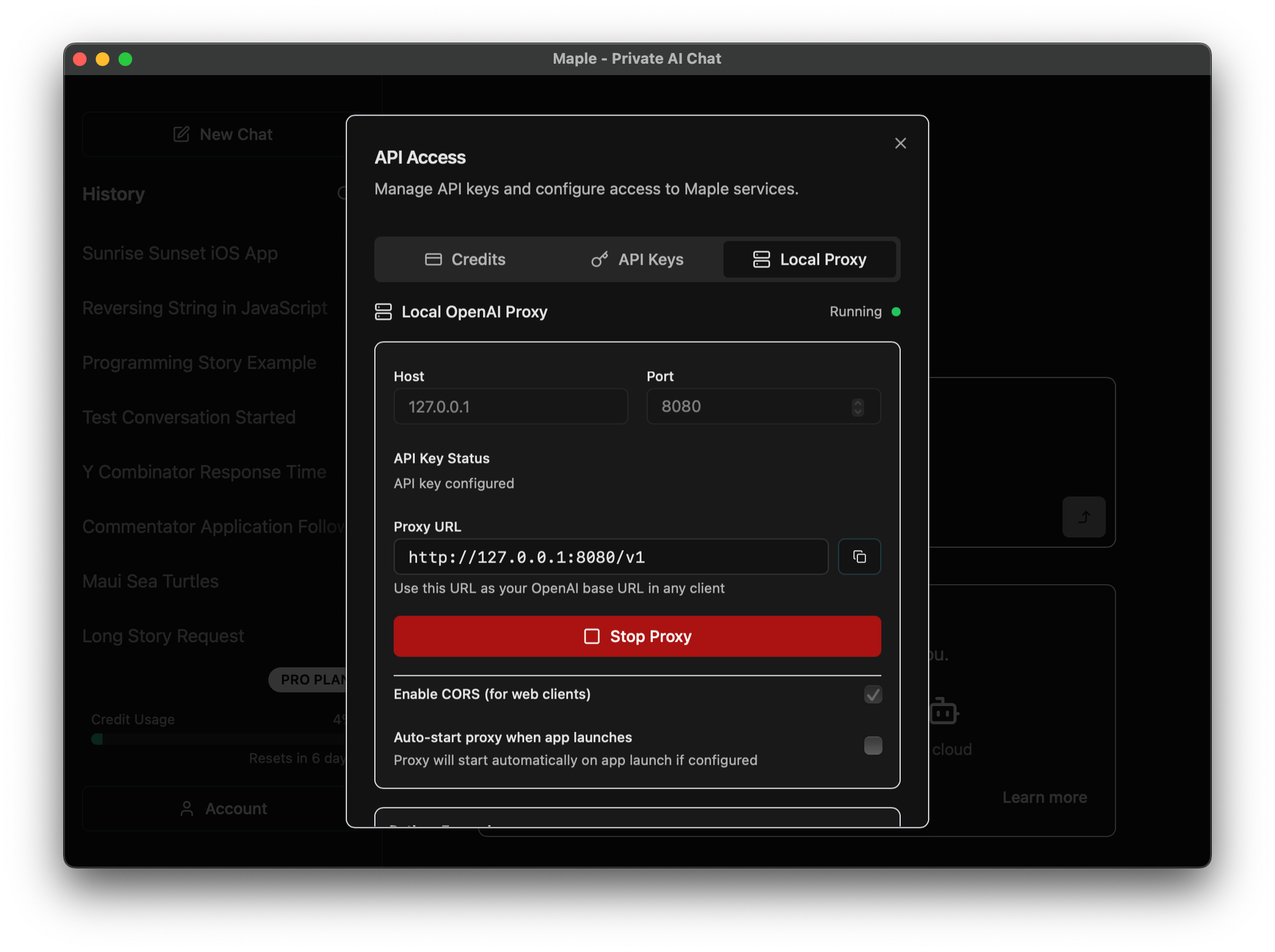
The desktop app will:
- Automatically create and manage API keys
- Start the proxy on
localhost:8080(configurable) - Handle all TEE attestation and encryption
- Show real-time proxy status and logs
Once running, simply point any OpenAI client to http://localhost:8080/v1:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8080/v1",
api_key="auto-configured-by-desktop-app"
)
response = client.chat.completions.create(
model="llama-3.3-70b",
messages=[{"role": "user", "content": "Hello, secure world!"}],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end="")
Option 2: Standalone Docker Deployment (Best for Production)
For production deployments or CI/CD pipelines, use the standalone Maple Proxy Docker image:
- Pull the Docker image:
docker pull ghcr.io/opensecretcloud/maple-proxy:latest
- Create an API key in your Maple account at trymaple.ai
- Run the proxy:
docker run -p 8080:8080 \
-e MAPLE_BACKEND_URL=https://enclave.trymaple.ai \
ghcr.io/opensecretcloud/maple-proxy:latest
- Use with your API key:
import OpenAI from 'openai';
const client = new OpenAI({
baseURL: 'http://localhost:8080/v1',
apiKey: 'your-maple-api-key'
});
const response = await client.chat.completions.create({
model: 'gpt-oss-120b',
messages: [{ role: 'user', content: 'Explain TEEs in simple terms' }],
stream: true
});
for await (const chunk of response) {
process.stdout.write(chunk.choices[0]?.delta?.content || '');
}
Docker Compose for Production
For production deployments with proper configuration management:
version: '3.8'
services:
maple-proxy:
image: ghcr.io/opensecretcloud/maple-proxy:latest
container_name: maple-proxy
ports:
- "8080:8080"
environment:
- MAPLE_BACKEND_URL=https://enclave.trymaple.ai
- MAPLE_ENABLE_CORS=true
- RUST_LOG=info
# Note: In production, clients should provide their own API keys
# Do NOT set MAPLE_API_KEY here for multi-user deployments
restart: unless-stopped
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health"]
interval: 30s
timeout: 3s
retries: 3
API Endpoints
Maple Proxy implements the core OpenAI API endpoints:
List Available Models
curl http://localhost:8080/v1/models \
-H "Authorization: Bearer YOUR_MAPLE_API_KEY"
Create Chat Completion
curl -N http://localhost:8080/v1/chat/completions \
-H "Authorization: Bearer YOUR_MAPLE_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "llama-3.3-70b",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a haiku about privacy"}
],
"stream": true
}'
Note: Maple currently supports streaming responses only. All completions will be streamed back to your client.
Client Library Examples
Python
from openai import OpenAI
# For desktop app with auto-configured proxy
client = OpenAI(
base_url="http://localhost:8080/v1",
api_key="any-string" # Desktop app handles auth
)
# For standalone proxy
client = OpenAI(
base_url="http://localhost:8080/v1",
api_key="your-maple-api-key"
)
# Streaming is required for all requests
response = client.chat.completions.create(
model="qwen3-coder-480b",
messages=[{"role": "user", "content": "Write a Python function to sort a list"}],
temperature=0.7,
max_tokens=500,
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")
Node.js/TypeScript
import OpenAI from 'openai';
const client = new OpenAI({
baseURL: 'http://localhost:8080/v1',
apiKey: process.env.MAPLE_API_KEY
});
// Streaming example with TypeScript
async function streamCompletion() {
const stream = await client.chat.completions.create({
model: 'deepseek-r1-0528',
messages: [{ role: 'user', content: 'Solve this step by step: 25 * 4 + 10' }],
stream: true,
});
for await (const chunk of stream) {
process.stdout.write(chunk.choices[0]?.delta?.content || '');
}
}
Any OpenAI-Compatible Tool
Since Maple Proxy implements the OpenAI API specification, it works with any tool that supports custom OpenAI endpoints:
- LangChain: Set
openai_api_base="http://localhost:8080/v1" - LlamaIndex: Configure
api_base="http://localhost:8080/v1" - Amp: Add custom OpenAI provider with Maple Proxy URL
- Open Interpreter: Configure with
--api_base http://localhost:8080/v1 - Goose: Block's AI developer agent - configure with Maple Proxy endpoint
- And many more...
Production Best Practices
For Local Development
- Use the Maple desktop app for automatic proxy management
- The desktop app handles API key management and configuration
- Enable auto-start in the desktop app for convenience
For Production Deployments
- Use the standalone Docker image for better resource isolation
- Never hardcode API keys in your deployment configuration
- Each client/user should provide their own Maple API key
- Monitor the
/healthendpoint for service availability - Use environment variables or secrets management for API keys
Security Considerations
- API keys are tied to your Maple user account and usage is billed accordingly
- Treat API keys like passwords, never commit them to version control
- Rotate keys regularly using the Maple dashboard
- For multi-tenant applications, require each tenant to provide their own key
How It Works Under the Hood
When you make a request through Maple Proxy:
- Client Request: Your OpenAI client sends a standard API request to the proxy
- TEE Handshake: Proxy establishes a secure connection with Maple's TEE infrastructure
- Attestation: Proxy verifies the TEE's attestation to ensure genuine secure hardware
- Encryption: Your request is encrypted end-to-end before transmission
- Authentication: Proxy validates your Maple API key
- Processing: The LLM processes your request inside the secure enclave
- Response: Encrypted response is decrypted by the proxy and returned in OpenAI format
All of this happens transparently, your application just sees a standard OpenAI API response.
Getting Help
- GitHub: github.com/opensecretcloud/maple-proxy - Report issues and contribute
- Discord: Join our community for support and discussions
- Documentation: Full API reference and examples available in the repository
Start Building with Private AI Today
Maple Proxy makes it simple to add private, secure AI capabilities to your applications without sacrificing developer experience. Whether you're building a chatbot, code assistant, or AI-powered analytics tool, you can now do it with the confidence that your data remains completely private.
Get started in minutes:
- Download Maple or pull the Docker image
- Sign up for a Pro account ($20/month)
- Start building with any OpenAI-compatible client
Your code stays the same. Your data stays private.
Welcome to the future of secure AI development.



